
This is the second in a series of posts on quantifying the impact of business drivers on sales volume. Please review these posts for more information on this very useful analytical technique that helps answer the question Why did our volume change?
Part 1 – Overview of this very useful analytical technique that helps answer the question Why did our volume change?
Part 3 – Impact of Pricing
Part 4 – Impact of Trade
Part 5 – Impact of Competition
And then the final post in the series, Part 6 – Impact of Everything Else
This post focuses on quantifying the impact of Distribution, since that is often the biggest driver of volume. If a product’s not in distribution, shoppers can’t buy it!
In this example, we are explaining the 2.5% volume change for Magnificent Muffins, shown in the first line of the table below. I’ll walk through how to determine what the values are in the last 2 columns of the table below based on the change in Distribution and it’s elasticity. In future posts I’ll talk about some of the other drivers, but for now we are focusing only on Distribution, highlighted in blue in the table below.
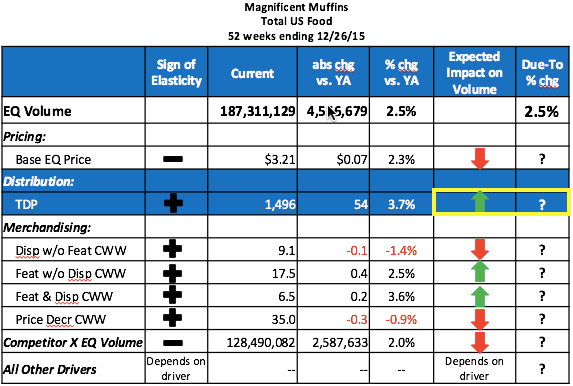
The measure I’ll use for distribution is TDPs (Total Distribution Points), which accounts for both how many stores carry your brand and how many items they carry. Here’s the relevant data from the table above:
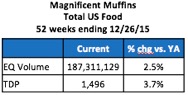
We see that volume sales are up +2.5% and distribution is up +3.7%. Since distribution is growing faster than volume, it means that something else is happening to the business to “drag it down.” Otherwise you’d suspect that volume would also be up at least +3.7%. The real question is: How much did the 3.7% increase in distribution contribute to the 2.5% volume growth?
I’ll show one way to calculate that below. (As with many things, there is more than one way to do this. I will try to keep it as simple as possible. Please feel free to ask questions about other methods you use or may have seen that are different.) But I need a little more information to complete the calculation: last year’s volume and a distribution elasticity.
Estimating Distribution Elasticity
A good rule of thumb for distribution elasticity is to assume something between 0.6 and 1.0. You may be wondering…how do I know that distribution elasticity is typically between 0.6 and 1.0? I’ve seen MANY of these and done this type of analysis across a wide variety of CPG categories and brands. The number will always be positive because if distribution goes up, then sales also go up. There is no way that putting your product in front of more people can hurt your volume! (It would take a whole other complicated post to get into how to calculate a more precise distribution elasticity. It essentially has to do with looking at the velocity over different periods of time and for different scenarios of how distribution is changing. I almost always just start with a 0.8 and then modify it as necessary once other drivers are also in the volume decomp analysis rather than doing a full-blown analysis to determine a more specific distribution elasticity each time.)
So we know the elasticity is greater than 0 but how much greater? Here are some other “principles” to keep in mind when deciding what elasticity to use for Distribution:
- If distribution for an established brand is growing because existing items are getting into more stores, then the elasticity tends to be towards the lower end of the range. This is because stores that take items later on are usually not as good as the stores that have had the item for while already.
- If distribution is growing for an established brand because additional items are getting into stores that already carry existing items, then the elasticity depends somewhat on how many items were already there. Adding an item to a line of 3 SKUs should have more of an impact (and higher elasticity) than adding an item to a line of 12 SKUs. The more items there are in the brand for the shopper to choose from, the harder it is for new items at shelf to be incremental, rather than replace something the shopper would have bought if the new item was not there.
- If an established brand is losing distribution, then the elasticity also tends to be lower since you would expect the items getting delisted to contribute less to volume. After all, they are usually getting delisted for a good reason such as limited consumer appeal.
If a brand (or the category itself) is still relatively new and gaining distribution, then the value is probably closer to the higher end of the range. It makes sense that a new item has to have at least average sales in the category otherwise why would retailers take it and keep it on the shelf? Sometimes the elasticity for a new brand can change over time, depending on which retailers take it early vs. later. A good rule of thumb for distribution elasticity in an annual due-to is 0.9.
Calculating The Impact of Distribution on Volume
To calculate the impact of distribution on volume, follow the numbered steps in the following table.
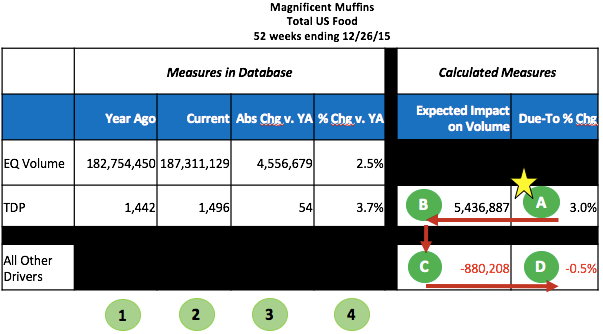
The first 4 data columns are facts that are available in most IRI/Nielsen DBs or can be easily calculated from what is available:
- Year ago = value during the same period a year ago
- Current = value in current year
- Abs Chg v. YA = absolute change vs. year ago = Current – Year Ago
- % chg vs. YA = % change vs. year ago = (Current – Year ago) / Year Ago = Abs Chg v. YA / Year Ago
The last 2 columns are “new” measures that I’m calculating and the calculations do happen in this order. In this example, I’ll assume an elasticity of 0.8.
- Due-to % Chg for Distribution = % chg vs. YA * elasticity = 3.7% * 0.8 = 3.0%. You can say that of the 2.5% gain in volume, more than all of it (3.0%!) was due to an increase in distribution. Note that this is different than +3.7% increase in the distribution itself.
- Expected Impact on Volume of Distribution = Due-To % Chg * Year Ago EQ Volume = 3.0% * 182,754,450 = 5,436,887. You can say that of the more than 4.5 million LB increase in volume, more than 5.4 million LBS were due to an increase in distribution.
- Expected Impact on Volume of All Other Drivers = Abs Chg in Volume – Expected Impact on Volume of Distribution = 4,556,679 – 5,436,887 = -880,208. Because distribution accounted for more than the actual volume change, the impact of all the other drivers have to be negative.
- Due-to % Chg for All Other Drivers = Expected Impact on Volume of All Other Drivers / Year Ago EQ Volume = -880,208 / 182,754,450 = -0.5%. Notice that the sum of the Due-To % Chg measures for Distribution and All Other Drivers is the same as the % Chg vs. YA for EQ Volume.
So to summarize…in this example, I am estimating that a 3.7% increase in distribution was responsible for a 3.0% increase in volume. Said another way, if nothing else changed besides distribution, Magnificent Muffin volume would have grown by 3.0%. That means the All Other bucket, including everything BUT distribution, had a negative impact on volume. In future posts, I’ll pull some more drivers out of the All Other bucket to shed more light on what might be hurting volume. Future posts will add more drivers to the analysis (pricing, merchandising and advertising) but there will almost always be an All Other bucket, since we do not have data for all possible business drivers.
Did you find this article useful? Subscribe to CPG Data Tip Sheet to get future posts delivered to your email in-box. We publish articles about once a month. We will not share your email address with anyone.
Hi, Robin,
Thank you so much for this great post! It is extremely helpful. Just wanted to make sure that you actually assume elasticity of 0.9 instead of 0.8, correct?
Due-to % Chg for Distribution = % chg vs. YA * elasticity = 3.7% * 0.9 = 3.0%.
Could you please write a post to talk about how to calculate a more precise distribution elasticity? It will be very very helpful for the people like me who is less experienced and lack of a good rule of thumb.
Thank you so much!
Thanks for catching that error in the explanation! It is now corrected in the post above. Good to know people are actually reading our posts in such detail!
The next few posts will be about including other drivers in the volume decomp analysis so I can get to how to calculate a distribution elasticity later on this year.
Thank you for reading the CPG Data Tip Sheet!
I can say people really are hooked to your website. These are some awesome blog-posts and inexperienced folks do get a lot of insights.
I wonder if you could do a series on what kind of SMART charts/reports would a retailer be really interested for optimizing assortment. I know it’s a broad topic and that’s the reason I have written SMART in front of that. You can really be innovative in those posts and can take your loyal readers on really good ride.
Cheers!
G
Thanks for the kind words!
For assortment optimization, there are many different assortment/space management software packages available to retailers and manufacturers that include plan-o-grams (abbreviated POGs) and other visualizations. Retailers have different priorities and goals than manufacturers when it comes to assortment and shelf space, and you really need to think about those 2 things together. There are usually graphs showing some combination of volume, revenue and profit for the whole category and on a per foot basis.
We do have a series of posts on graphs in general that you may find helpful. Search for the phrase “Picture This:” in the search box on the blog. Unfortunately Sally and I do not have access to real POG data, which makes for the best posts. If we come across anything, though, we’ll write about it!
Robin i need to understand about % share of distribution? i am confused reading data on low alcohol beer, all 3 brands sales are declining but on the other hand no alcohol beer sales is increasing.
It sounds to me like the 3 brands you are looking at may not add up to the whole category of No Alcohol Beer. Also, I’m not sure how share of distribution is related. If you want to discuss further please fill out the Contact form (at the upper right on the blog) and we can schedule a quick call to discuss.
TDP does not account for the number of stores, it accounts for the percent of grocery business (ACV). That’s an important distinction. A Walmart Supercenter has a much higher ACV than a Walmart Neighborhood store than a small-format Walmart, yet each would count as one store.
Sales do not always go up as distribution goes up. If you spent your trade dollars getting distribution in new outlets rather than supporting the brand, it’s entirely possible that your sales will not increase. Indeed, if you pulled enough support, you could see a decrease in sales (hopefully temporary).
The statement that late accepters are worse for you, sales-wise, than early accepters may or may not be true; it depends on the players who are early and late. If Walmart takes you late, that could be a big boost to sales. You potentially confuse a weak-selling item getting de-listed versus a brand getting de-listed – the latter leads to a higher elasticity.
Here’s what really concerns me – this process yields a made-up number that has no validity. Just by assuming a different elasticity, I can completely change the implications of the analysis. For example, if I use 0.6 as my elasticity, then my “due-to” percent change is 2.2%, which means my other activities had a positive effect. This is in contrast to your example where “other activities” would be hurting sales.
There is a simple and correct way to do this. Split your store sample into buckets; those who are new distributors, those who are old and have increased items carried, and those who are old and have discontinued items. Look at their sales this year v. last year and you’ll see what distribution does for you.
Thanks for your comment and for reading the CPG Data Tip Sheet.
You make many valid points, all of which I am well aware. The purpose of the post was to explain a MUCH simplified way to quantify the impact of distribution on volume. (A previous post explained the overall concept of doing a volume decomposition and future posts will address the other drivers.) One key takeaway is that you should not look at drivers in isolation and assume that a single thing was responsible for a volume increase or decline. There are, of course, the art and science portions of completing a volume decomposition and I have spent whole days training people in person with their own data on how to do this.
To address some specific points:
1. There is a link in the post all about the real meaning of TDPs. I used the shorthand “number of stores and how many items.” I just want to make sure that readers understand I’m taking into account both the breadth (%ACV) and depth (# items) of distribution. Of course not all stores are created equal, when it comes to distribution.
2. The whole point of doing a volume decomp is to allocate a volume change to as many different drivers as your data allows. Your example of changing trade spending is valid if money was spent on getting distribution in channels/retailers not covered by IRI/Nielsen. If the trade spending went down on actual trade activity (not as many events or less of a discount or TPR instead of Quality) then the Trade driver would be negative, which is in the All Other bucket in my analysis.
3. You are right about the order of “acceptors” affecting the distribution elasticity. In the interest of simplicity (and based on my experience), it is possible that later stores are better for sales but not nearly as common. Walmart is typically at the earlier end of accepting new products while some other retailers like to wait and see how it does in Walmart first. Of course timing of new item acceptance also depends on the aisle/category reset calendar of each retailer.
3. Regarding the “made-up” number for distribution elasticity…I have all the other drivers that will be in the analysis and can tell what elasticity to use for distribution. Again, based on what I have seen over the years, starting with 0.8 and then tweaking from there once all the other drivers are also in the analysis is often the easiest/fastest way to do this.
4. Your suggestion of the “simple and correct way to do this” has 2 issues, if I understand what you’re saying. The most important is that you can’t just look at stores that increased distribution vs. those that did not or discontinued items and say the difference in sales is due to the difference in distribution. That does not take into account anything else that may have been happening differently in the 2 groups of stores. What if the stores that increased distribution also lowered the price? What if there were also in-store demos in those stores? It would be unfair (to those other tactics) to attribute all the sales increase to distribution. The other problem with that suggestion is that I am not using store-level data. The analysis I describe can be done at the Total US, channel, market or retailer level. I agree that you can do an analysis across retailers to see what generally happens when items are added/delisted but you would still want to control for other things happening at the same time.
Thanks for your interest in this topic! If you would be willing, we are happy to have a guess post if you’d like to explain in more detail how to do the analysis you mentioned using store-level data. I’m sure may of our readers would find that very helpful. Please let me know (via email or the Contact Us form on the blog) if you’d like to discuss that further.
Nice article. One question – if I were to be a regression model with all drivers that affect sales, can I use the coefficients to estimate elasticity of each driver, including the coeff for distribution? [Of course, depending on the functional form of the reg model — normal additive vs. log-log, etc]
In theory a regression is one way to get to coefficients but…a volume decomp is typically conducted for fairly long time periods – annual or quarterly, sometimes monthly. The problem arises because you need a certain number of observations relative to the number of variables in a regression model. So, if you are doing a volume decomp for an annual period you probably only have 3 historic periods, if you’re looking at quarters then you’ll have 12 historic periods. Even with months you would have 24-36 months (depending on how much history is on your IRI/Nielsen database). Most databases have 2-3 years of history. If you develop a regression using weekly data (with plenty of observations), then you cannot apply the coefficients from that in a volume decomp for a longer period since the coefficient will represent the change for a single week. As you can probably tell, this is a complicated topic and I just wanted to introduce it to our audience! Let me know if you’d like to discuss this further. Hope this helps!
Also, I’m curious if it’s a new item how do I calculate due-to? Elasticity multiplied by change in distribution? Since it’s a new item, the change in distribution will be 100%, correct?
You can’t calculate a good due-to on a new item or brand. I guess you could say 100% of the sales are due-to distribution since no sales could happen if there was no distribution! There is no easy way to parse out distribution vs. other things to market the new product – price, advertising, shopper marketing, etc. One way to decompose the volume of a new item brand is by doing a marketing mix study, which is way more complex than just doing some quick calculations in Excel. There are whole firms that only do marketing mix! You may want to check what Nielsen and IRI, plus some other boutique firms say about it.
The Elasticity and the Coeff we use are same or different?
You can think of elasticity and coefficient as the same thing in this context – some factor that is used in conjunction with the change in a driver to get the corresponding change in volume. Technically speaking I think an elasticity refers to the factor used with the % change in the driver to get a % change in the volume. You’ll see in later posts that sometimes we’ll use a factor with and absolute number to get to an absolute change in volume (like LBS per week of support for Trade activity).
Hi Robin, Thanks for starting this series. I am eagerly waiting for calculations for other drivers. I have few questions. (1) Does the elasticity numbers change based on country and category? OR do they tend to be the similar irrespective? (2) If I were to calculate the elasticity numbers by myself, how much historic data would you suggest, to get the elasticity number? (3) In the above table, only TDP, Feat w/o Disp CWW, Feat & Disp CWW are the only drivers that really contributed to the growth. So, is there a way we can calculate the contributions of only these 3 drivers (to make it 100% of the growth). This is because, since other drivers have declined they haven’t contributed/contributed negatively to the growth.
Really appreciate your answers. Many Thanks
Here are some answers for you:
1. Elasticities definitely change by category and country, although I would think that the range is fairly similar for distribution elasticity, between maybe 0.6 and 1.0.
2. The key to using history to calculate an elasticity is that you need to see enough instances of the distribution changing. It’s possible to have 2 years of history when the distribution hardly changed. In that case, you can’t accurately estimate how much volume changes in response to a change in distribution.
3. Even though only 3 of the drivers contributed to the growth, those actually contributed more than 100% of the total growth because the other drivers had a minimal or negative impact. I guess you could prorate the 3 positive volume drivers to 100% but that is not usually done, as people typically also want to know how the other things also affected volume.
Hope that helps!
Hello Robin,
Firstly, I’m confident I am not alone when I say that CPG analysts everywhere are thankful for CPGDataInsights.com. The platform has helped me as a developing analyst on countless occasions with its insight, its clarity, and its accessibility.
Quick question with respect to your numbers. I’m trying to recreate elements of your volume decomposition calculates but am running into some confusion. Specifically, when calculating “Expected Impact on Volume of Distribution”.
“Expected Impact on Volume of Distribution” = Due-To % Change x Year Ago EQ Volume. Okay, I get that. However, when I multiple 3.0% by 182,754,450, I don’t get 5,436,887. The result is exactly 5,482,633.50. If I reverse your calculation to identify the Due-To Chg %, as you have above, 5,436,887 / 182,754,450, I get 2.975% (rounded figure). Naturally, that rounds essentially to 3.0%. However, that number varies from the actual calculation of the Due-To Chg % for TDP, which is Elasticity x % Chg vs. YAGO for TDP, which is 2.996%. I also used an elasticity value of 0.8 in my calculation.
I hope the explanation is lucid enough and articulates the source of my confusion accurately.
Respectfully,
Alex
I think the issue is all about rounding, as you suspect. I honestly do not remember if I rounded and then did the calculations or vice versa. It is standard practice to report % change numbers to one decimal place so 3.0% is “the same as” 2.975% and 2.996%. More decimal places that that (or too many digits when talking about millions of pounds or units) gives a false sense of precision to the accuracy of an analysis. Hope that helps!
I have a question because I’m not completely sure if I’m doing something right.
So one product, in one particular market, actually did quite well. We pushed our points of distribution, increasing it by ~400%. We also ~tripled our volume. So I’m getting a due to of 294.1% for distribution. Just to clarify, this means “If we did nothing else with this SKU in this market other than increase TDP by 400%, we would have seen a 294.1% increase in EQ volume?”
Thanks!
Yes! That seems like you are interpreting the impact of the 400% increase in distribution on volume correctly. Your statement implies that you are using a distribution elasticity of 0.735, since +400% for distribution x 0.735 = +294% volume. And I like how you said “almost/about tripled our volume” instead of “increased our volume by 294%.” 😉
Wonderful! Thanks! I did some volume decomp work years ago with the Nielsen guidelines, but you not only explain it so well, but you’ve expanded upon the value of what they propose much better. Thank you for all the work you do.
Hello,
Is there a detailed post on how do we precisely calculate the distribution elasticity.
Thanks,
Venkat
I have not written a post on how to calculate a more precise distribution elasticity. It involves looking at data over a long enough period of time where the distribution itself has changed. If you want to discuss on the phone, please fill use the Contact Us form and we can set up a call.
Hi Robin,
Amazing article !!
I have a question on the drivers of Numeric Distribution for a brand. Could you please shared your thoughts on the same, look forward to urgently hear from you.
Thanks
anshu
Numeric Distribution is found on databases outside the US and Canada. It is the % of Stores where the item or brand or manufacturer is present. So if the brand is present in 600 stores out of 1,000 stores (for that channel) for example, then it has a 60% numerical distribution (regardless of how well the stores are performing). “Selling Numeric Distribution” the % of stores that actually sold the product during the period, not just the stores that carried it.
I’m wondering if, instead of estimating elasticity, I could multiply the ACD Pt Chg by $ SPPD (more specifically YA $ SPPD to control for things that impacted velocity in the current year). It’s so simple I must be missing something…but it seems like a similar approach to the one used in Part 4.
You could do what you suggest but then I think there is double-counting. All the other drivers impact the velocity.
Really amazing post! This website has been foundational in learning about CPG.
If I want to make the decomposition even more granular, is it possible to split out TDP into the effect of adding more items and the effect of increasing ACV?
Basically, I want to decomp distribution into depth(# skus on shelf) and breadth (#of stores)
Thanks!
Thanks for the kind words! Glad you are finding the blog helpful.
Yes, you can go a level deeper to get to impact of depth vs. breadth of distribution but it’s not simple and would be hard to explain in a quick response. Please use the Contact form on the blog and I’d be happy to set up a phone call to discuss.